Update instructions
This commit is contained in:
parent
1fd53b854b
commit
fce8ba8ddf
|
|
@ -14,7 +14,7 @@
|
|||
or excluded items with the `*` wildcard
|
||||
- No spying - Czkawka does not have access to the Internet, nor does it collect any user information or statistics
|
||||
- Multiple tools to use:
|
||||
- Duplicates - Finds duplicates based on file name, size, hash, hash of just first 1 MB of a file
|
||||
- Duplicates - Finds duplicates based on file name, size or hash
|
||||
- Empty Folders - Finds empty folders with the help of an advanced algorithm
|
||||
- Big Files - Finds the provided number of the biggest files in given location
|
||||
- Empty Files - Looks for empty files across the drive
|
||||
|
|
@ -31,6 +31,8 @@
|
|||
## How do I use it?
|
||||
You can find the instructions on how to use Czkawka [**here**](instructions/Instruction.md).
|
||||
|
||||
Some helpful tricks you can find [**here**](instructions/Instruction.md#tips-tricks-and-known-bugs)
|
||||
|
||||
## Installation
|
||||
Installation instructions with download links you can find [**here**](instructions/Installation.md).
|
||||
|
||||
|
|
@ -118,7 +120,7 @@ Bleachbit is a master at finding and removing temporary files, while Czkawka onl
|
|||
|
||||
## Other apps
|
||||
There are many similar applications to Czkawka on the Internet, which do some things better and some things worse.
|
||||
- [DupeGuru](https://github.com/arsenetar/dupeguru) - A lot of options to customize
|
||||
- [DupeGuru](https://github.com/arsenetar/dupeguru) - A lot of options to customize, great photo compare tool
|
||||
- [FSlint](https://github.com/pixelb/fslint) - A little outdated, but still have some tools not available in Czkawka
|
||||
- [Fclones](https://github.com/pkolaczk/fclones) - One of the fastest tools to find duplicates, it is written also in Rust but only in CLI
|
||||
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ pub enum Commands {
|
|||
minimal_cached_file_size: u64,
|
||||
#[structopt(flatten)]
|
||||
allowed_extensions: AllowedExtensions,
|
||||
#[structopt(short, long, default_value = "HASH", parse(try_from_str = parse_checking_method), help = "Search method (NAME, SIZE, HASH, HASHMB)", long_help = "Methods to search files.\nNAME - Fast but but rarely usable,\nSIZE - Fast but not accurate, checking by the file's size,\nHASHMB - More accurate but slower, checking by the hash of the file's first mebibyte\nHASH - The slowest method, checking by the hash of the entire file")]
|
||||
#[structopt(short, long, default_value = "HASH", parse(try_from_str = parse_checking_method), help = "Search method (NAME, SIZE, HASH)", long_help = "Methods to search files.\nNAME - Fast but but rarely usable,\nSIZE - Fast but not accurate, checking by the file's size,\nHASH - The slowest method, checking by the hash of the entire file")]
|
||||
search_method: CheckingMethod,
|
||||
#[structopt(short = "D", long, default_value = "NONE", parse(try_from_str = parse_delete_method), help = "Delete method (AEN, AEO, ON, OO, HARD)", long_help = "Methods to delete the files.\nAEN - All files except the newest,\nAEO - All files except the oldest,\nON - Only 1 file, the newest,\nOO - Only 1 file, the oldest\nHARD - create hard link\nNONE - not delete files")]
|
||||
delete_method: DeleteMethod,
|
||||
|
|
@ -305,7 +305,7 @@ fn parse_checking_method(src: &str) -> Result<CheckingMethod, &'static str> {
|
|||
"name" => Ok(CheckingMethod::Name),
|
||||
"size" => Ok(CheckingMethod::Size),
|
||||
"hash" => Ok(CheckingMethod::Hash),
|
||||
_ => Err("Couldn't parse the search method (allowed: NAME, SIZE, HASH, HASHMB)"),
|
||||
_ => Err("Couldn't parse the search method (allowed: NAME, SIZE, HASH)"),
|
||||
}
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -40,7 +40,10 @@ At the end execute it:
|
|||
```
|
||||
|
||||
**Warning**
|
||||
If you use want to use app on ARM machine e.g. Mac M1, you can't use prebuilt binaries, because they were compiled for x86_64 architecture. You need to compile Czkawka manually to get proper binaries.
|
||||
Prebuilt binaries are available only for x86_64, so if you use ARM machine like e.g. Mac M1, you need to compile manually app or install special version of required libraries which can be done via this:
|
||||
```shell
|
||||
arch -x86_64 /usr/local/bin/brew install gtk+3 adwaita-icon-theme ffmpeg librsvg
|
||||
```
|
||||
|
||||
### Windows
|
||||
By default, all needed libraries are bundled with the app, inside `windows_czkawka_gui.zip`, but if you compile the app or just move `czkawka_gui.exe`, then you will need to install the `GTK 3`
|
||||
|
|
|
|||
|
|
@ -85,18 +85,23 @@ Windows - `C:\Users\Username\AppData\Local\Qarmin\Czkawka\cache`
|
|||
|
||||
## Tips, Tricks and Known Bugs
|
||||
- **Manually adding multiple directories**
|
||||
You can manually edit config file `czkawka_gui_config.txt` and add/remove/change directories as you want. After setting required values, configuration must be loaded to Czkawka.
|
||||
- **Slow checking of little number similar images**
|
||||
If you checked before a large number of images (several tens of thousands) and they are still present on the disk, then the required information about all of them is loaded from and saved to the cache, even if you are working with only few image files. You can rename one of cache file which starts from `cache_similar_image`(to be able to use it again) or delete it - cache will then regenerate but with smaller number of entries and this way it should load and save a lot of faster.
|
||||
- **Not all columns are visible**
|
||||
You can manually edit config file `czkawka_gui_config.txt` and add/remove/change directories as you want. After set required values, configuration must be loaded to Czkawka.
|
||||
- **Slow checking of little number similar images/duplicates/broken files**
|
||||
If you checked before a large number of files (several tens of thousands), then the required information about all of them are loaded and saved to the cache, even if you are working with only few files. You can rename one of cache file which starts from `cache_similar_image`(to be able to use it again) or delete it - cache will then regenerate but with smaller number of entries and this way it should load and save cache faster.
|
||||
- **Not all columns are always visible**
|
||||
For now it is possible that some columns will not be visible when some are too wide. There are 2 workarounds for now
|
||||
- View can be scrolled via horizontal scroll bar
|
||||
- Size of other columns can be slimmed
|
||||
- View can be scrolled via horizontal scroll bar (1 on image)
|
||||
- Size of other columns can be slimmed (2 )
|
||||
This is checked if is possible to do in https://github.com/qarmin/czkawka/issues/169
|
||||
- **Opening parent folders**
|
||||
- It is possible to open parent folder of selected items with double click with right mouse button(RMB) - it is also possible to open such item with double click with left mouse buttom(LMB).
|
||||
|
||||
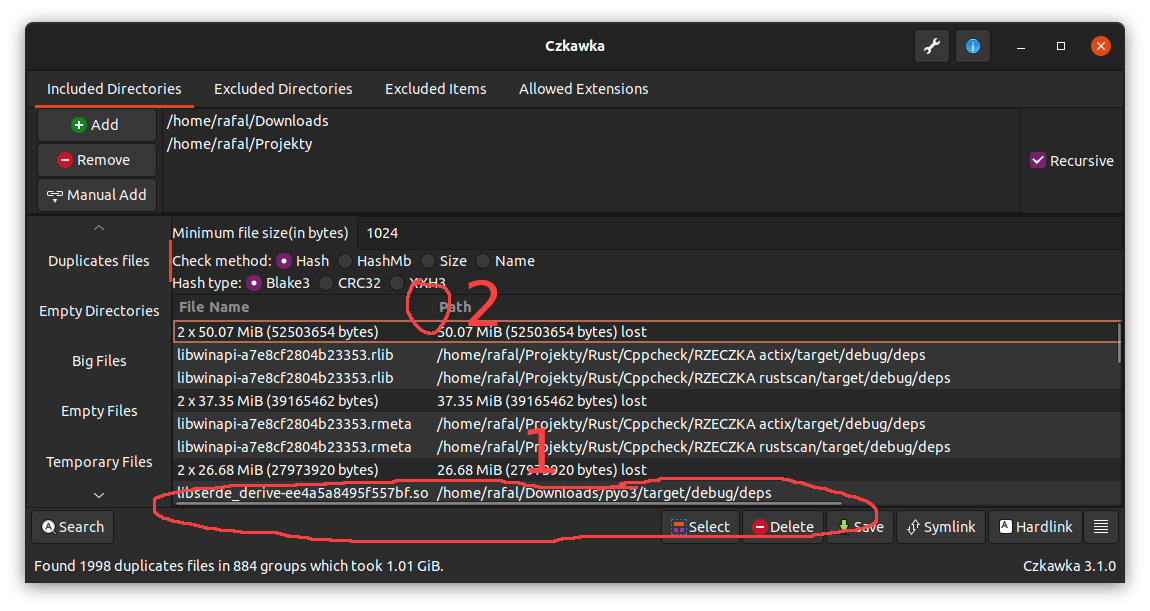
|
||||
- **Opening parent folders**
|
||||
- It is possible to open parent folder of selected items with double click with right mouse button(RMB)
|
||||
it is also possible to open such item with double click with left mouse button(LMB).
|
||||
- **Faster scanning for big number of duplicates**
|
||||
By default for all files grouped by same size are computed partial hash(hash from only of 2KB each file). Such hash is computed usually very fast, especially on SSD and fast multicore processors. But when scanning a hundred of thousands or millions of files with HDD or slow processor, usually this step can take much time. In settings exists option `Use prehash cache` which enables caching such things. It is disabled by default because can increase time of loading/saving cache, with big number of entries.
|
||||
- **Permanent store of cache entries**
|
||||
After each scan, entries in cache are validated and outdated ones(which points at non-existent files) are removed. This may be problematic when scanning external drivers(like pendrives, disks etc.) and later unplugging and plugging them again. In settings exists option `Delete outdated cache entries automatically` which automatically clear this, but this can be disabled. Disabling such option may create big cache files, so button `Remove outdated results` will do it manually.
|
||||
|
||||
|
||||
# Tools
|
||||
|
||||
|
|
@ -237,7 +242,8 @@ Some tidbits:
|
|||
Tool works similar as Similar Images.
|
||||
|
||||
To work require `FFmpeg`, so it will show an error when it is not found in OS.
|
||||
Also only checks files which are longer than 30s.
|
||||
Also only checks files which are longer than 30s.
|
||||
For now it is limiting to check video files with almost equal length.
|
||||
|
||||
At first, it collects video files by extension (`mp4`, `mpv`, `avi` etc.).
|
||||
Next each file is hashed. Implementation is hidden in library but looks that generate 10 images from this video and hash them with help of perceptual hash.
|
||||
|
|
@ -249,8 +255,8 @@ Next, with provided by user tolerance, they are compared to each other and group
|
|||
### Broken Files
|
||||
This tool finds files which are corrupted or have an invalid extension.
|
||||
|
||||
At first files from specific group (image,archive,audio) are collected and then these files are opened.
|
||||
At first files from specific group (image,archive,audio) are collected and then these files are opened(due to additional dependencies, audio files are disabled by default).
|
||||
|
||||
If an error happens when opening such file it means that this file is corrupted or unsupported.
|
||||
|
||||
Only some file extensions are supported, because I rely on external crates. Also, some false positives may be shown(e.g. https://github.com/image-rs/jpeg-decoder/issues/130) so always open file to check if it is really broken.
|
||||
Only some file extensions are handled, because I rely on external crates. Also, some false positives may be shown(e.g. https://github.com/image-rs/jpeg-decoder/issues/130) so always open file to check if it is really broken.
|
||||
|
|
|
|||
Loading…
Reference in a new issue