diff --git a/README.md b/README.md
index a707005a..4214ef56 100644
--- a/README.md
+++ b/README.md
@@ -641,16 +641,17 @@ It also includes a built-in scheduled import feature with `archivebox schedule`
## Output Formats: What ArchiveBox saves for each URL
+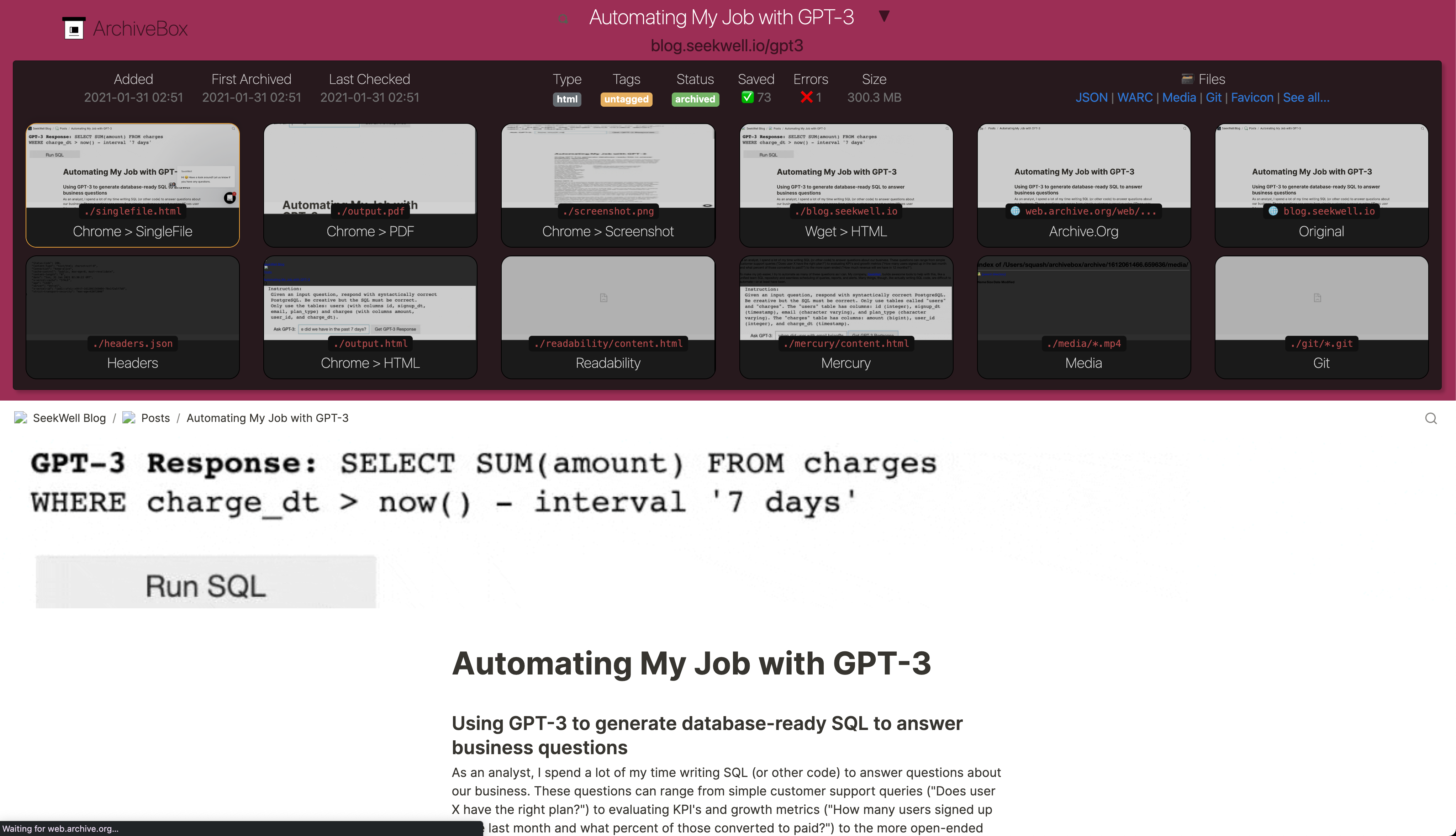 -Inside each Snapshot folder, ArchiveBox saves many different types of extractor outputs as plain files (e.g. HTML, PDF, PNG, JSON, WARC, etc.).
-It does everything out-of-the-box by default, but you can disable or tweak [individual archive methods](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) via environment variables / config.
+For each URL added, ArchiveBox preserves its content as plain files within a folder (e.g. HTML, PDF, PNG, JSON, etc.).
+
+It uses all methods out-of-the-box, but you can disable methods and fine-tune the [configuration](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed.
-Inside each Snapshot folder, ArchiveBox saves many different types of extractor outputs as plain files (e.g. HTML, PDF, PNG, JSON, WARC, etc.).
-It does everything out-of-the-box by default, but you can disable or tweak [individual archive methods](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) via environment variables / config.
+For each URL added, ArchiveBox preserves its content as plain files within a folder (e.g. HTML, PDF, PNG, JSON, etc.).
+
+It uses all methods out-of-the-box, but you can disable methods and fine-tune the [configuration](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed.
Expand to see the full list of ways ArchiveBox saves each page...
-
./archive/{Snapshot.id}/