diff --git a/README.md b/README.md
index c5a3d5f7..4c58a194 100644
--- a/README.md
+++ b/README.md
@@ -33,19 +33,19 @@ curl -sSL 'https://get.archivebox.io' | sh # (or see pip/brew/Docker instruct
**ArchiveBox is a powerful, self-hosted internet archiving solution to collect, save, and view websites offline.**
-Without active preservation effort, everything on the internet eventually dissapears or gets taken down. Archive.org does a great job, but as a large public central archive they can't save anything that requires a login.
+Without active preservation effort, everything on the internet eventually dissapears or degrades. Archive.org does a great job as a free public central archive, but they can't save anything that requires a login.
*ArchiveBox helps you save web content offline for a variety of situations: download old family photos off Flickr, preserve evidence for legal cases, backup an old Soundcloud mix, snapshot papers for academic research, and more...*
> ➡️ *Use ArchiveBox as a [command-line package](#quickstart) and/or [self-hosted web app](#quickstart) on Linux, macOS, or in [Docker](#quickstart).*
-
+
-**You can feed ArchiveBox URLs one at a time, or schedule regular imports** from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
+📥 **You can feed ArchiveBox URLs one at a time, or schedule regular imports** from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
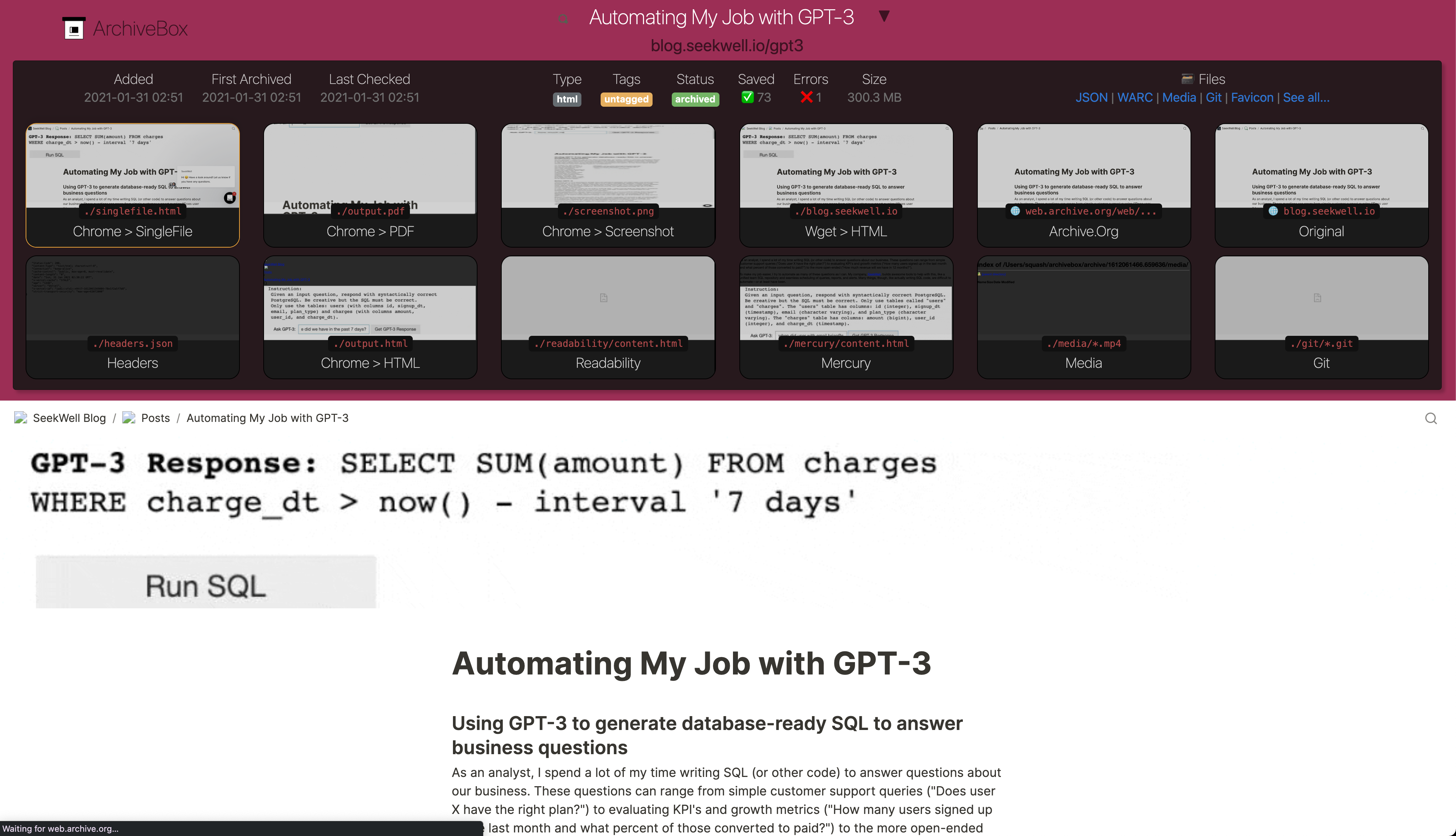 -**It saves offline-viewable snapshots of the URLs you feed it in a few redundant formats.**
+💾 **It saves offline-viewable snapshots of the URLs you feed it in a few redundant formats.**
It also auto-detects the content featured *inside* each webpage extracts it out to common, easy file formats:
- `HTML/Generic Websites -> HTML/PDF/PNG/WARC`
- `YouTube/SoundCloud/etc. -> mp3/mp4`,
-**It saves offline-viewable snapshots of the URLs you feed it in a few redundant formats.**
+💾 **It saves offline-viewable snapshots of the URLs you feed it in a few redundant formats.**
It also auto-detects the content featured *inside* each webpage extracts it out to common, easy file formats:
- `HTML/Generic Websites -> HTML/PDF/PNG/WARC`
- `YouTube/SoundCloud/etc. -> mp3/mp4`,