diff --git a/README.md b/README.md
index c3f8b843..6b9d127f 100644
--- a/README.md
+++ b/README.md
@@ -29,7 +29,7 @@ Without active preservation effort, everything on the internet eventually dissap
-📥 **You can feed ArchiveBox URLs one at a time, or schedule regular imports** from browser bookmarks or history, feeds like RSS, bookmark services like Pocket/Pinboard, and more. See input formats for a full list.
+📥 **You can feed ArchiveBox URLs one at a time, or schedule regular imports** from the browser [extension](https://chromewebstore.google.com/detail/archivebox-exporter/habonpimjphpdnmcfkaockjnffodikoj), bookmarks or history, social media feeds or RSS, link-saving services like Pocket/Pinboard, and more. See Input Formats for a full list.
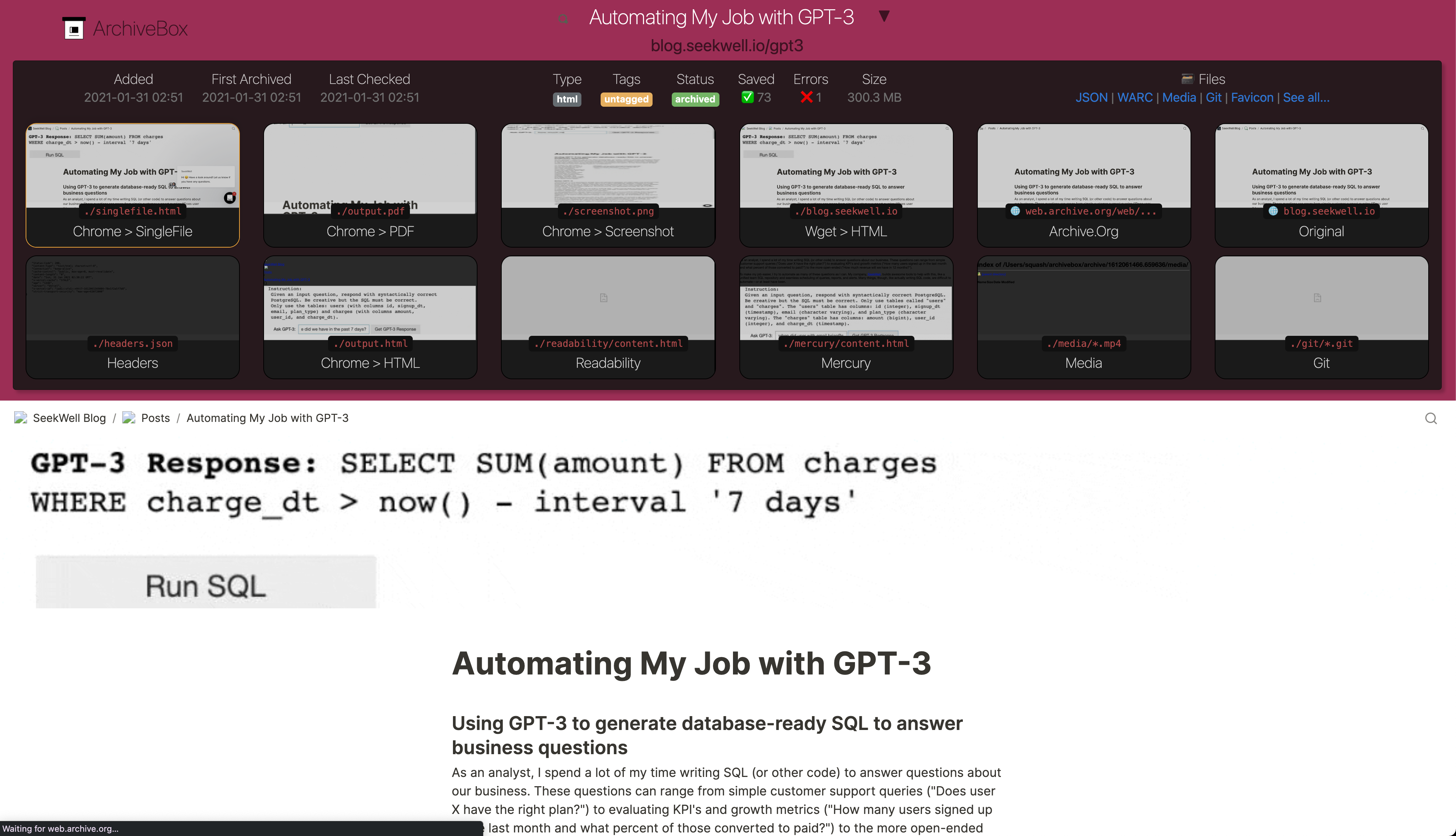 @@ -39,7 +39,7 @@ It also detects any content featured *inside* each webpage & extracts it out int
- 🎥 **Social Media**/**News** ➡️ `post content TXT`, `comments`, `title`, `author`, `images`
- 🎬 **YouTube**/**SoundCloud**/etc. ➡️ `MP3/MP4`s, `subtitles`, `metadata`, `thumbnail`, ...
- 💾 **Github**/**Gitlab**/etc. links ➡️ `clone of GIT source code`, `README`, `images`, ...
-- ✨ *[and more...](#output-formats)*
+- ✨ *and more, see all [Output Formats](#output-formats) below...*
It uses ordinary filesystem folders to organize archives (no complicated proprietary formats), and offers a CLI + web UI.
To power its functionality, ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be tuned, secured, and extended as-needed.
@@ -39,7 +39,7 @@ It also detects any content featured *inside* each webpage & extracts it out int
- 🎥 **Social Media**/**News** ➡️ `post content TXT`, `comments`, `title`, `author`, `images`
- 🎬 **YouTube**/**SoundCloud**/etc. ➡️ `MP3/MP4`s, `subtitles`, `metadata`, `thumbnail`, ...
- 💾 **Github**/**Gitlab**/etc. links ➡️ `clone of GIT source code`, `README`, `images`, ...
-- ✨ *[and more...](#output-formats)*
+- ✨ *and more, see all [Output Formats](#output-formats) below...*
It uses ordinary filesystem folders to organize archives (no complicated proprietary formats), and offers a CLI + web UI.
To power its functionality, ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be tuned, secured, and extended as-needed.