+

+
+
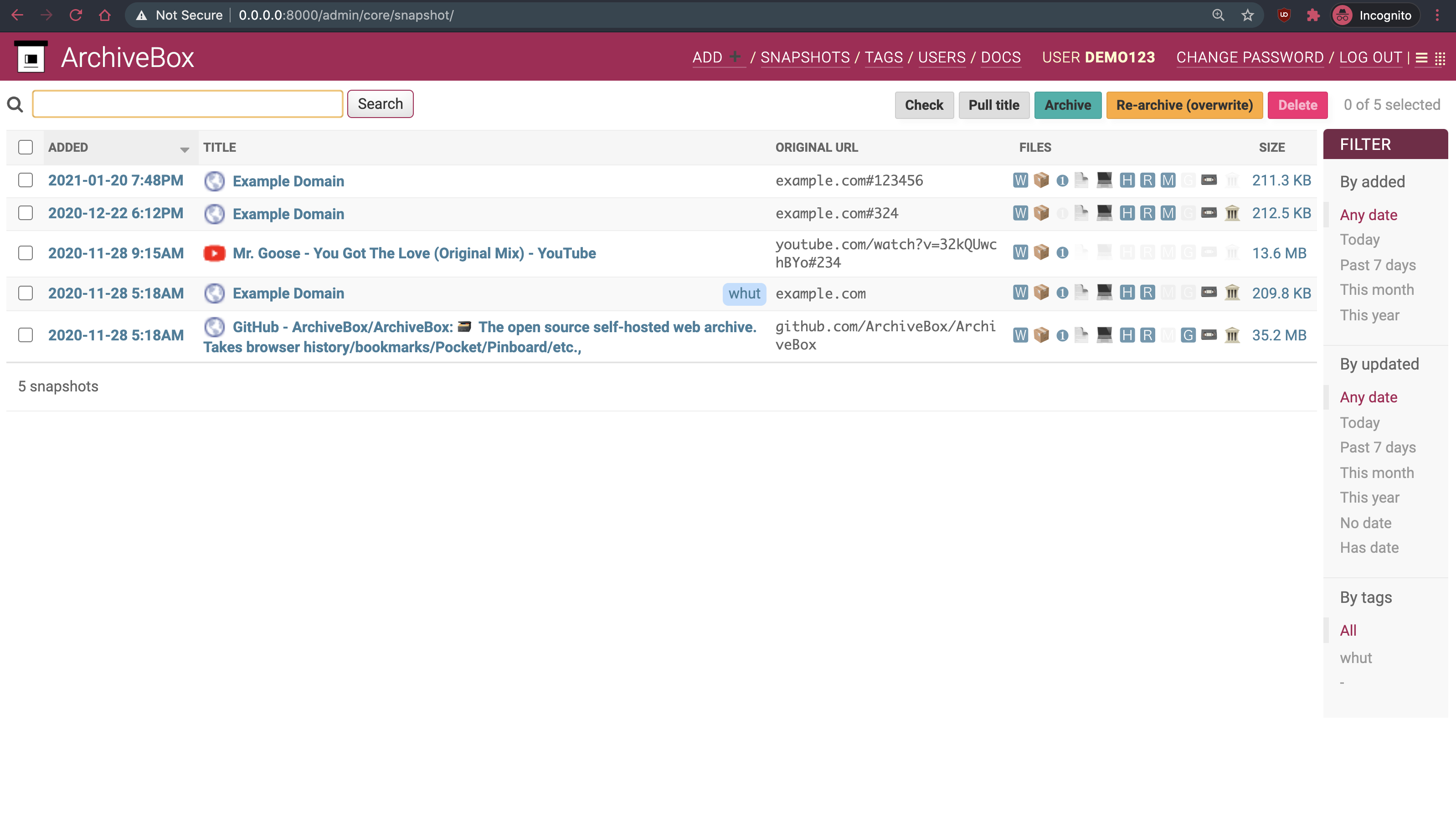
Demo | Screenshots | Usage
+
+
. . . . . . . . . . . . . . . . . . . . . . . . . . . .
+


@@ -116,7 +127,7 @@ curl -sSL 'https://get.archivebox.io' | sh
- [**Extracts a wide variety of content out-of-the-box**](https://github.com/ArchiveBox/ArchiveBox/issues/51): [media (yt-dlp), articles (readability), code (git), etc.](#output-formats)
- [**Supports scheduled/realtime importing**](https://github.com/ArchiveBox/ArchiveBox/wiki/Scheduled-Archiving) from [many types of sources](#input-formats)
- [**Uses standard, durable, long-term formats**](#output-formats) like HTML, JSON, PDF, PNG, MP4, TXT, and WARC
-- [**Usable as a oneshot CLI**](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#CLI-Usage), [**self-hosted web UI**](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#UI-Usage), [Python API](https://docs.archivebox.io/en/latest/modules.html) (BETA), [REST API](https://github.com/ArchiveBox/ArchiveBox/issues/496) (ALPHA), or [desktop app](https://github.com/ArchiveBox/electron-archivebox) (ALPHA)
+- [**Usable as a oneshot CLI**](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#CLI-Usage), [**self-hosted web UI**](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#UI-Usage), [Python API](https://docs.archivebox.io/en/latest/modules.html) (BETA), [REST API](https://github.com/ArchiveBox/ArchiveBox/issues/496) (ALPHA), or [desktop app](https://github.com/ArchiveBox/electron-archivebox)
- [**Saves all pages to archive.org as well**](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#save_archive_dot_org) by default for redundancy (can be [disabled](https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#stealth-mode) for local-only mode)
- Advanced users: support for archiving [content requiring login/paywall/cookies](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#chrome_user_data_dir) (see wiki security caveats!)
- Planned: support for running [JS during archiving](https://github.com/ArchiveBox/ArchiveBox/issues/51) to adblock, [autoscroll](https://github.com/ArchiveBox/ArchiveBox/issues/80), [modal-hide](https://github.com/ArchiveBox/ArchiveBox/issues/175), [thread-expand](https://github.com/ArchiveBox/ArchiveBox/issues/345)
@@ -128,17 +139,17 @@ curl -sSL 'https://get.archivebox.io' | sh
ArchiveBox is free for everyone to self-host, but we also provide support, security review, and custom integrations to help NGOs, governments, and other organizations [run ArchiveBox professionally](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102):
- 🗞️ **Journalists:**
- `crawling and collecting research`, `preserving quoted material`, `fact-checking and review`
+ `crawling during research`, `preserving cited pages`, `fact-checking & review`
- ⚖️ **Lawyers:**
- `collecting & preserving evidence`, `hashing / integrity checking / chain-of-custody`, `tagging & review`
+ `collecting & preserving evidence`, `detecting changes`, `tagging & review`
- 🔬 **Researchers:**
- `analyzing social media trends`, `collecting LLM training data`, `crawling to feed other pipelines`
+ `analyzing social media trends`, `getting LLM training data`, `crawling pipelines`
- 👩🏽 **Individuals:**
- `saving legacy social media / memoirs`, `preserving portfolios / resume`, `backing up news articles`
+ `saving bookmarks`, `preserving portfolio content`, `legacy / memoirs archival`
-> ***[Contact our team](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102)** if your institution/org wants to use ArchiveBox professionally.*
+> ***[Contact our team](https://zulip.archivebox.io/#narrow/stream/167-enterprise/topic/welcome/near/1191102)** if your institution/org wants to use ArchiveBox professionally. We offer services such as:*
>
-> - setup & support, team permissioning, hashing, audit logging, backups, custom archiving etc.
+> - setup & support, hosting, custom features, security, hashing & audit logging for chain-of-custody, etc.
> - for **individuals**, **NGOs**, **academia**, **governments**, **journalism**, **law**, and more...
*We are a 🏛️ 501(c)(3) nonprofit and all our work goes towards supporting open-source development.*
@@ -154,7 +165,7 @@ ArchiveBox is free for everyone to self-host, but we also provide support, secur
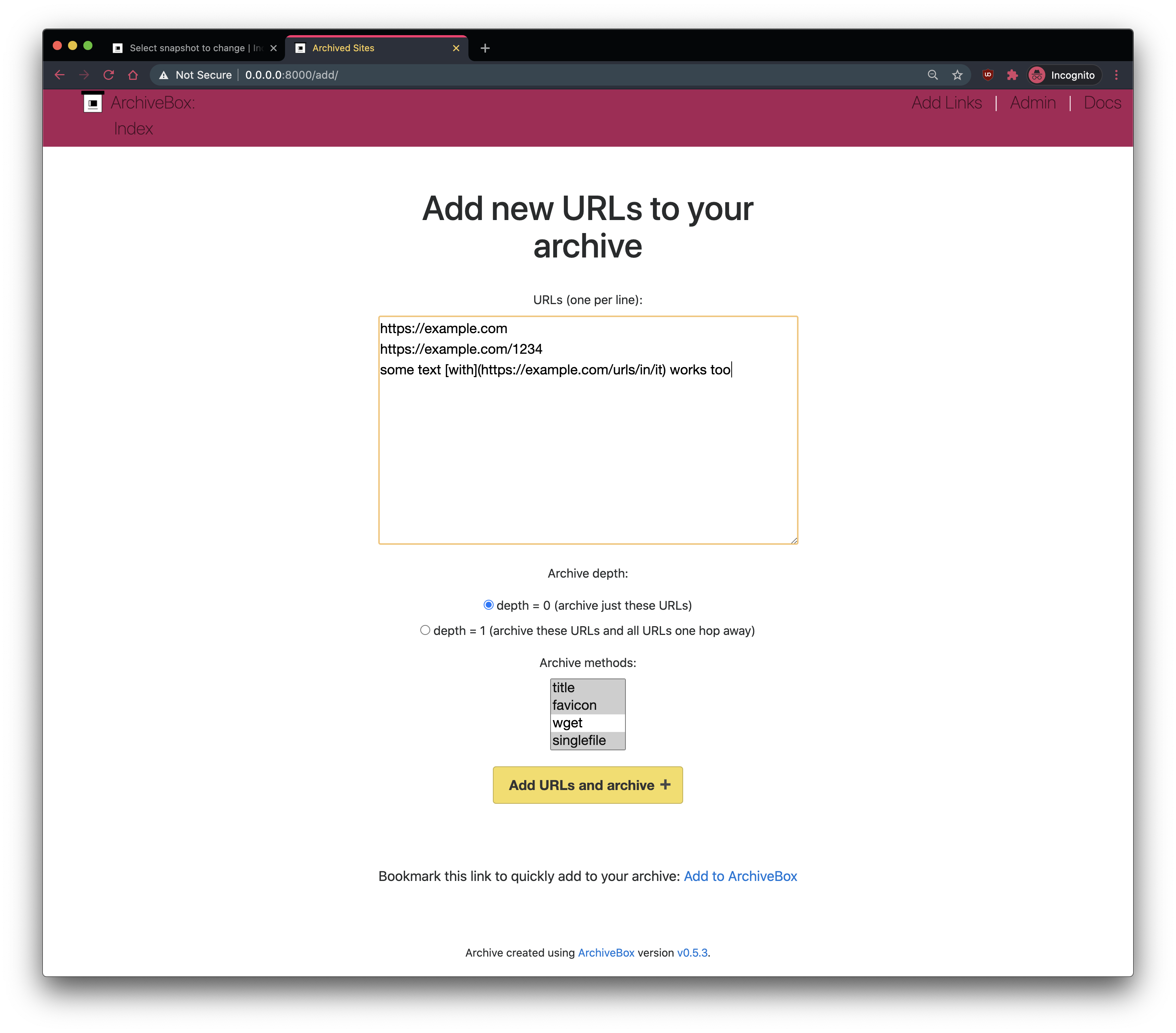
# Quickstart
-**🖥 Supported OSs:** Linux/BSD, macOS, Windows (Docker) **👾 CPUs:** `amd64` (`x86_64`), `arm64` (`arm8`), `arm7`
(raspi>=3)
+**🖥 Supported OSs:** Linux/BSD, macOS, Windows (Docker) **👾 CPUs:** `amd64` (`x86_64`), `arm64`, `arm7`
(raspi>=3)
Note: On `arm7` the `playwright` package is not available, so `chromium` must be installed manually if needed.
@@ -164,7 +175,7 @@ ArchiveBox is free for everyone to self-host, but we also provide support, secur

docker-compose (macOS/Linux/Windows) 👈 recommended (click to expand)
-👍 Docker Compose is recommended for the easiest install/update UX + best security + all the extras out-of-the-box.
+👍 Docker Compose is recommended for the easiest install/update UX + best security + all extras out-of-the-box.
- Install Docker on your system (if not already installed).
@@ -334,8 +345,7 @@ See the homebr

pacman / 
pkg / 
nix (Arch/FreeBSD/NixOS/more)
-> [!WARNING]
-> *These are contributed by external volunteers and may lag behind the official `pip` channel.*
+> *Warning: These are contributed by external volunteers and may lag behind the official `pip` channel.*
- TrueNAS / YunoHost / Cloudron / UNRAID / etc. (self-hosting solutions)
TrueNAS / YunoHost / Cloudron / UNRAID / etc. (self-hosting solutions)
+ TrueNAS / UNRAID / YunoHost / Cloudron / etc. (self-hosting solutions)
-> [!WARNING]
-> *These are contributed by external volunteers and may lag behind the official `pip` channel.*
+> *Warning: These are contributed by external volunteers and may lag behind the official `pip` channel.*
- TrueNAS
@@ -401,7 +410,7 @@ See below for usage examples using the CLI, W
(get hosting, support, and feature customization directy from us)
-
 - (for a generalist software consultancy that helps with ArchiveBox maintainance)
- (for a generalist software consultancy that helps with ArchiveBox maintainance)
+ (generalist consultancy that has ArchiveBox experience)
Other providers of paid ArchiveBox hosting (not officially endorsed):
@@ -432,7 +441,7 @@ For more discussion on managed and paid hosting options see here: (depending on how you chose to install it above)
```bash
mkdir -p ~/archivebox/data # create a new data dir anywhere
@@ -460,16 +470,19 @@ docker compose run archivebox help
#### ArchiveBox Subcommands
-- `archivebox` `help`/`version` to see the list of available subcommands and currently installed version info
-- `archivebox` `setup`/`init`/`config`/`status`/`manage` to administer your collection
-- `archivebox` `add`/`schedule`/`remove`/`update`/`list`/`shell`/`oneshot` to manage Snapshots in the archive
-- `archivebox` `schedule` to pull in fresh URLs regularly from [bookmarks/history/Pocket/Pinboard/RSS/etc.](#input-formats)
+- `archivebox` `help`/`version` to see the list of available subcommands / currently installed version info
+- `archivebox` `setup`/`init`/`config`/`status`/`shell`/`manage` to administer your collection
+- `archivebox` `add`/`oneshot`/`schedule` to pull in fresh URLs from [bookmarks/history/RSS/etc.](#input-formats)
+- `archivebox` `list`/`update`/`remove` to manage existing Snapshots in your collection
 CLI Usage Examples (non-Docker)
CLI Usage Examples (non-Docker)
+# make sure you have pip-installed ArchiveBox and it's available in your $PATH first
+
+# archivebox [subcommand] [--args]
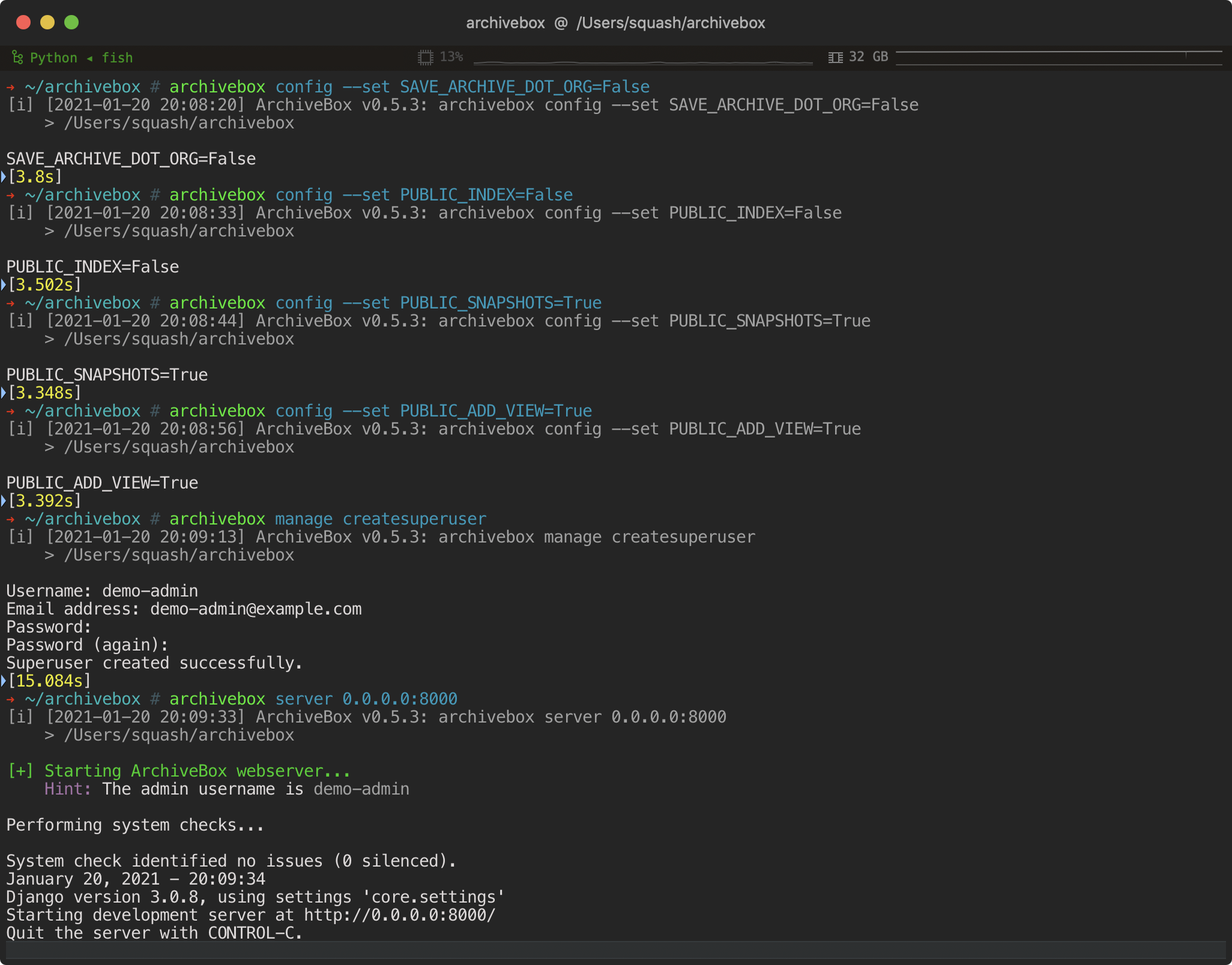
archivebox init --setup # safe to run init multiple times (also how you update versions)
archivebox version # get archivebox version info + check dependencies
archivebox help # get list of archivebox subcommands that can be run
@@ -484,6 +497,8 @@ archivebox add --depth=1 'https://news.ycombinator.com'
# make sure you have `docker-compose.yml` from the Quickstart instructions first
+
+# docker compose run archivebox [subcommand [--args]
docker compose run archivebox init --setup
docker compose run archivebox version
docker compose run archivebox help
@@ -498,6 +513,9 @@ docker compose run archivebox add --depth=1 'https://news.ycombinator.com'
Docker CLI Usage Examples
+# make sure you create and cd into in a new empty directory first
+
+# docker run -it -v $PWD:/data archivebox/archivebox [subcommand [--args]
docker run -v $PWD:/data -it archivebox/archivebox init --setup
docker run -v $PWD:/data -it archivebox/archivebox version
docker run -v $PWD:/data -it archivebox/archivebox help
@@ -601,16 +619,20 @@ docker run -it -v $PWD:/data archivebox/archivebox add --depth=1 'https://exampl
## Input Formats: How to pass URLs into ArchiveBox for saving
--  The official ArchiveBox Browser Extension (provides realtime archiving from Chrome/Chromium/Firefox browsers)
+- From the official ArchiveBox Browser Extension
+ Provides realtime archiving of browsing history or selected pages from Chrome/Chromium/Firefox browsers.
--
The official ArchiveBox Browser Extension (provides realtime archiving from Chrome/Chromium/Firefox browsers)
+- From the official ArchiveBox Browser Extension
+ Provides realtime archiving of browsing history or selected pages from Chrome/Chromium/Firefox browsers.
--  Manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
+- From manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, etc. files
+ ArchiveBox supports injesting URLs in [any text-based format](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file).
--
Manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, or [any other text-based format...](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file)
+- From manual imports of URLs from RSS, JSON, CSV, TXT, SQL, HTML, Markdown, etc. files
+ ArchiveBox supports injesting URLs in [any text-based format](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Import-a-list-of-URLs-from-a-text-file).
--  [MITM Proxy](https://mitmproxy.org/) archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy)
+-
[MITM Proxy](https://mitmproxy.org/) archiving with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy) ([realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy)
+-  From manually exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (in Netscape format)
+ See instructions for: Chrome, Firefox, Safari, IE, Opera, and more...
-- Exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
-
--
From manually exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (in Netscape format)
+ See instructions for: Chrome, Firefox, Safari, IE, Opera, and more...
-- Exported [browser history](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) or [browser bookmarks](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive) (see instructions for: [Chrome](https://support.google.com/chrome/answer/96816?hl=en), [Firefox](https://support.mozilla.org/en-US/kb/export-firefox-bookmarks-to-backup-or-transfer), [Safari](https://github.com/ArchiveBox/ArchiveBox/assets/511499/24ad068e-0fa6-41f4-a7ff-4c26fc91f71a), [IE](https://support.microsoft.com/en-us/help/211089/how-to-import-and-export-the-internet-explorer-favorites-folder-to-a-32-bit-version-of-windows), [Opera](https://help.opera.com/en/latest/features/#bookmarks:~:text=Click%20the%20import/-,export%20button,-on%20the%20bottom), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive))
-
--  Links from [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
+- From URLs visited through a [MITM Proxy](https://mitmproxy.org/) with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy)
+ Provides [realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy.
+- From bookmarking services or social media (e.g. Twitter bookmarks, Reddit saved posts, etc.)
+ See instructions for: Pocket, Pinboard, Instapaper, Shaarli, Delicious, Reddit Saved, Wallabag, Unmark.it, OneTab, Firefox Sync, and more...
Links from [Pocket](https://getpocket.com/export), [Pinboard](https://pinboard.in/export/), [Instapaper](https://www.instapaper.com/user), [Shaarli](https://shaarli.readthedocs.io/en/master/Usage/#importexport), [Delicious](https://www.groovypost.com/howto/howto/export-delicious-bookmarks-xml/), [Reddit Saved](https://github.com/csu/export-saved-reddit), [Wallabag](https://doc.wallabag.org/en/user/import/wallabagv2.html), [Unmark.it](http://help.unmark.it/import-export), [OneTab](https://www.addictivetips.com/web/onetab-save-close-all-chrome-tabs-to-restore-export-or-import/), [Firefox Sync](https://github.com/ArchiveBox/ArchiveBox/issues/648), [and more...](https://github.com/ArchiveBox/ArchiveBox/wiki/Quickstart#2-get-your-list-of-urls-to-archive)
+- From URLs visited through a [MITM Proxy](https://mitmproxy.org/) with [`archivebox-proxy`](https://github.com/ArchiveBox/archivebox-proxy)
+ Provides [realtime archiving](https://github.com/ArchiveBox/ArchiveBox/issues/577) of all traffic from any device going through the proxy.
+- From bookmarking services or social media (e.g. Twitter bookmarks, Reddit saved posts, etc.)
+ See instructions for: Pocket, Pinboard, Instapaper, Shaarli, Delicious, Reddit Saved, Wallabag, Unmark.it, OneTab, Firefox Sync, and more...
 @@ -650,7 +672,7 @@ It uses all available methods out-of-the-box, but you can disable extractors and
@@ -650,7 +672,7 @@ It uses all available methods out-of-the-box, but you can disable extractors and
-Expand to see the full list of ways ArchiveBox saves each page...
+Expand to see the full list of ways it saves each page...
./archive/{Snapshot.id}/
@@ -666,7 +688,7 @@ It uses all available methods out-of-the-box, but you can disable extractors and
Article Text: article.html/json Article text extraction using Readability & Mercury
Archive.org Permalink: archive.org.txt A link to the saved site on archive.org
-Audio & Video: media/ all audio/video files + playlists, including subtitles & metadata with youtube-dl (or yt-dlp)
+Audio & Video: media/ all audio/video files + playlists, including subtitles & metadata w/ yt-dlp
Source Code: git/ clone of any repository found on GitHub, Bitbucket, or GitLab links
More coming soon! See the Roadmap...
@@ -677,7 +699,7 @@ It uses all available methods out-of-the-box, but you can disable extractors and
 -ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf` directly.
+ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf`.
-ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf` directly.
+ArchiveBox can be configured via environment variables, by using the `archivebox config` CLI, or by editing `./ArchiveBox.conf`.
Expand to see examples...
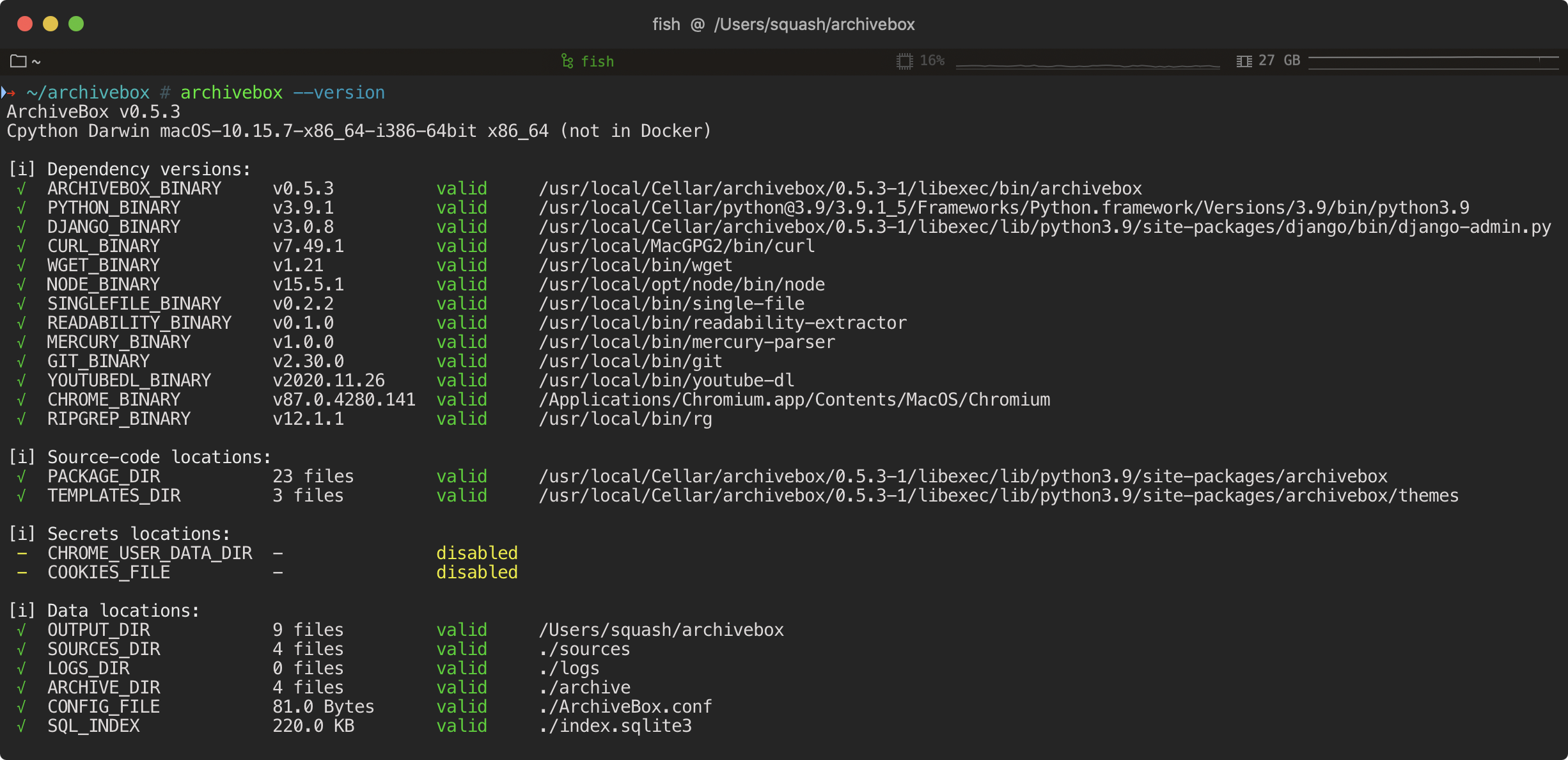
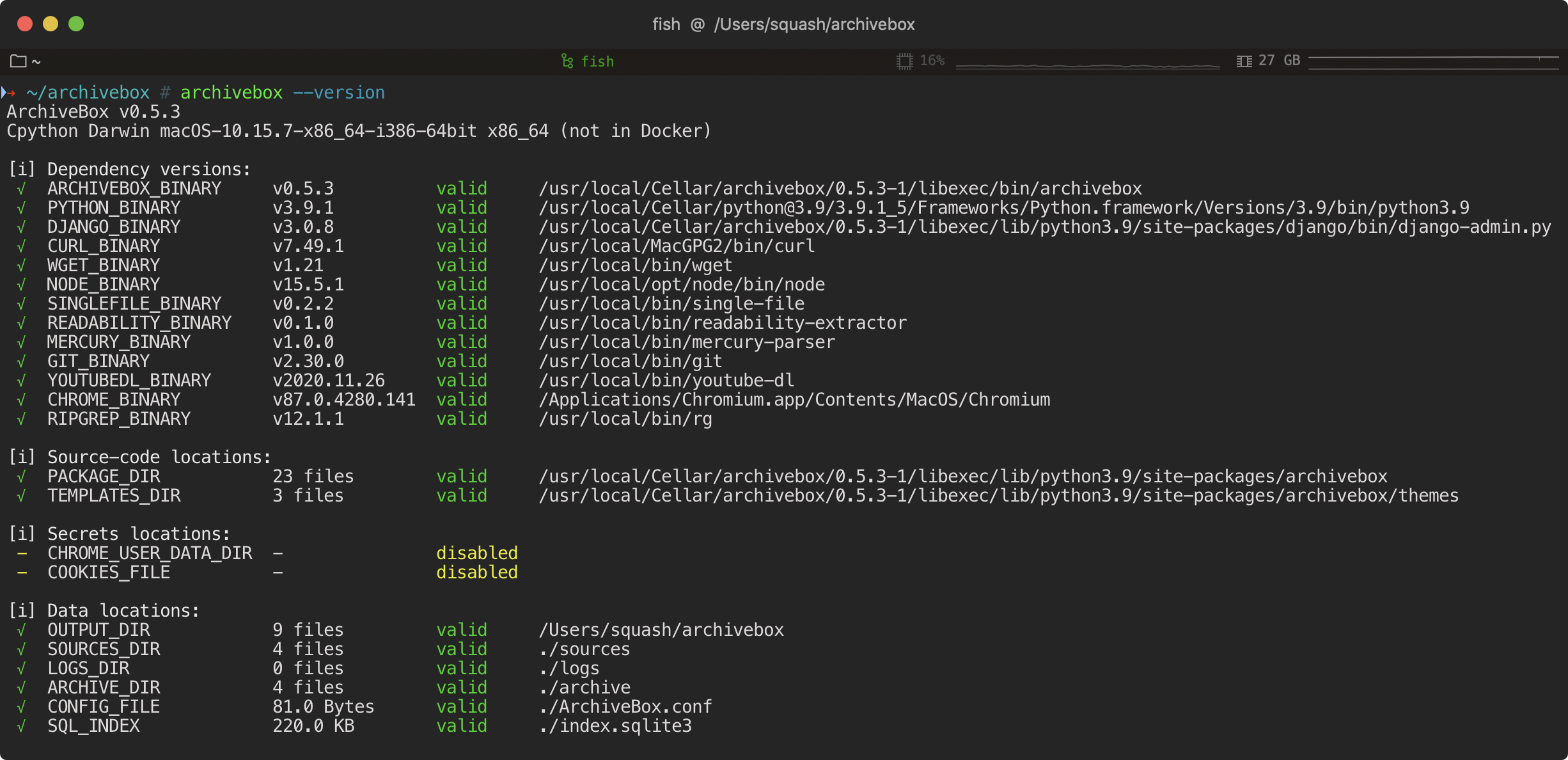
@@ -722,51 +744,55 @@ CURL_USER_AGENT="Mozilla/5.0 ..."
To achieve high-fidelity archives in as many situations as possible, ArchiveBox depends on a variety of 3rd-party libraries and tools that specialize in extracting different types of content.
-> Under-the-hood, ArchiveBox uses [Django](https://www.djangoproject.com/start/overview/) to power its [Web UI](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#ui-usage) and [SQlite](https://www.sqlite.org/locrsf.html) + the filesystem to provide [fast & durable metadata storage](https://www.sqlite.org/locrsf.html) w/ [determinisitc upgrades](https://stackoverflow.com/a/39976321/2156113). ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be [tuned, secured, and extended](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed for many different applications.
+> Under-the-hood, ArchiveBox uses [Django](https://www.djangoproject.com/start/overview/) to power its [Web UI](https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#ui-usage) and [SQlite](https://www.sqlite.org/locrsf.html) + the filesystem to provide [fast & durable metadata storage](https://www.sqlite.org/locrsf.html) w/ [determinisitc upgrades](https://stackoverflow.com/a/39976321/2156113).
+ArchiveBox bundles industry-standard tools like [Google Chrome](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install), [`wget`, `yt-dlp`, `readability`, etc.](#dependencies) internally, and its operation can be [tuned, secured, and extended](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration) as-needed for many different applications.
Expand to learn more about ArchiveBox's internals & dependencies...
-> *TIP: For better security, easier updating, and to avoid polluting your host system with extra dependencies,**it is strongly recommended to use the [⭐️ official Docker image](https://github.com/ArchiveBox/ArchiveBox/wiki/Docker)** with everything pre-installed for the best experience.*
+
+TIP: For better security, easier updating, and to avoid polluting your host system with extra dependencies,it is strongly recommended to use the ⭐️ official Docker image with everything pre-installed for the best experience.
+
These optional dependencies used for archiving sites include:
- +
+
+
+
+chromium / chrome (for screenshots, PDF, DOM HTML, and headless JS scripts)node & npm (for readability, mercury, and singlefile)wget (for plain HTML, static files, and WARC saving)curl (for fetching headers, favicon, and posting to Archive.org)yt-dlp or youtube-dl (for audio, video, and subtitles)git (for cloning git repos)singlefile (for saving into a self-contained html file)postlight/parser (for discussion threads, forums, and articles)readability (for articles and long text content)- and more as we grow...
+
-- `chromium` / `chrome` (for screenshots, PDF, DOM HTML, and headless JS scripts)
-- `node` & `npm` (for readability, mercury, and singlefile)
-- `wget` (for plain HTML, static files, and WARC saving)
-- `curl` (for fetching headers, favicon, and posting to Archive.org)
-- `yt-dlp` or `youtube-dl` (for audio, video, and subtitles)
-- `git` (for cloning git repos)
-- `singlefile` (for saving into a self-contained html file)
-- `postlight/parser` (for discussion threads, forums, and articles)
-- `readability` (for articles and long text content)
-- and more as we grow...
-
-You don't need to install every dependency to use ArchiveBox. ArchiveBox will automatically disable extractors that rely on dependencies that aren't installed, based on what is configured and available in your `$PATH`.
-
+You don't need to install every dependency to use ArchiveBox. ArchiveBox will automatically disable extractors that rely on dependencies that aren't installed, based on what is configured and available in your $PATH.
+
If not using Docker, make sure to keep the dependencies up-to-date yourself and check that ArchiveBox isn't reporting any incompatibility with the versions you install.
-```bash
-# install python3 and archivebox with your system package manager
+#install python3 and archivebox with your system package manager
# apt/brew/pip/etc install ... (see Quickstart instructions above)
-
+
archivebox setup # auto install all the extractors and extras
archivebox --version # see info and check validity of installed dependencies
-```
+
+
+Installing directly on Windows without Docker or WSL/WSL2/Cygwin is not officially supported (I cannot respond to Windows support tickets), but some advanced users have reported getting it working.
-Installing directly on **Windows without Docker or WSL/WSL2/Cygwin is not officially supported** (I cannot respond to Windows support tickets), but some advanced users have reported getting it working.
-
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Install#dependencies
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Upgrading-or-Merging-Archives
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Troubleshooting#installing
+Learn More
+
@@ -774,7 +800,7 @@ Installing directly on **Windows without Docker or WSL/WSL2/Cygwin is not offici
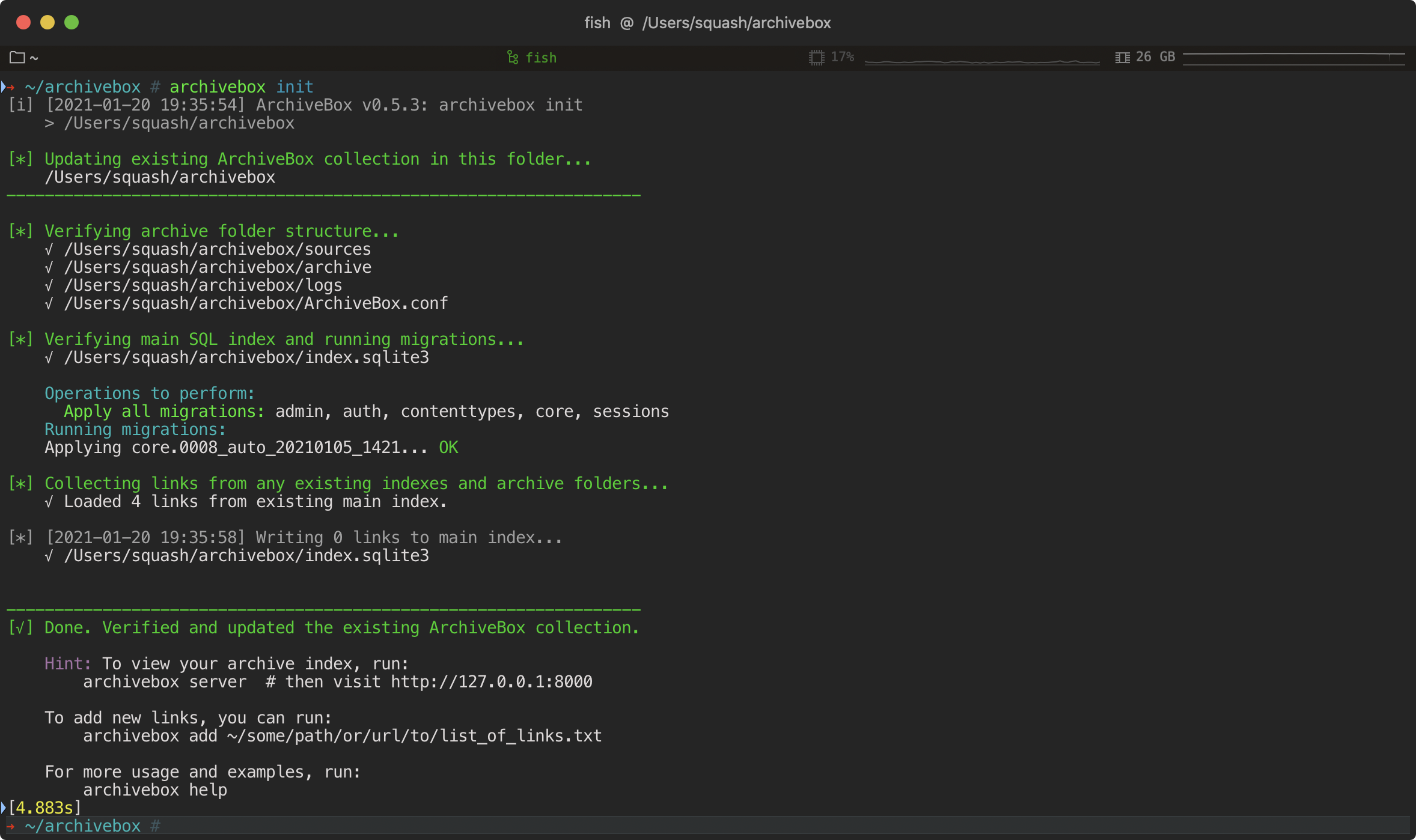
## Archive Layout
-All of ArchiveBox's state (SQLite DB, archived assets, config, logs, etc.) is stored in a single folder called the "ArchiveBox Data Folder".
+All of ArchiveBox's state (SQLite DB, content, config, logs, etc.) is stored in a single folder per collection.
@@ -810,11 +836,11 @@ Each snapshot subfolder ./archive/TIMESTAMP/ includes a static Learn More
@@ -823,17 +849,17 @@ Each snapshot subfolder ./archive/TIMESTAMP/ includes a static
Expand to learn how to export your ArchiveBox collection...
+
+NOTE: These exports are not paginated, exporting many URLs or the entire archive at once may be slow. Use the filtering CLI flags on the archivebox list command to export specific Snapshots or ranges.
+
-> *NOTE: These exports are not paginated, exporting many URLs or the entire archive at once may be slow. Use the filtering CLI flags on the `archivebox list` command to export specific Snapshots or ranges.*
-
-```bash|
-# do a one-off single URL archive wihout needing a data dir initialized
+# do a one-off single URL archive wihout needing a data dir initialized
archivebox oneshot 'https://example.com'
# archivebox list --help
@@ -843,16 +869,17 @@ archivebox list --csv=timestamp,url,title > index.csv # export to csv spreadshe
# (if using Docker Compose, add the -T flag when piping)
# docker compose run -T archivebox list --html 'https://example.com' > index.json
-```
+
The paths in the static exports are relative, make sure to keep them next to your `./archive` folder when backing them up or viewing them.
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Publishing-Your-Archive#2-export-and-host-it-as-static-html
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#publishing
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#public_index--public_snapshots--public_add_view
+Learn More
+
@@ -876,8 +903,7 @@ If you're importing pages with private content or URLs containing secret tokens
Expand to learn about privacy, permissions, and user accounts...
-```bash
-# don't save private content to ArchiveBox, e.g.:
+# don't save private content to ArchiveBox, e.g.:
archivebox add 'https://docs.google.com/document/d/12345somePrivateDocument'
archivebox add 'https://vimeo.com/somePrivateVideo'
@@ -893,19 +919,22 @@ archivebox manage createsuperuser
# if extra paranoid or anti-Google:
archivebox config --set SAVE_FAVICON=False # disable favicon fetching (it calls a Google API passing the URL's domain part only)
archivebox config --set CHROME_BINARY=chromium # ensure it's using Chromium instead of Chrome
-```
+
-> *CAUTION: Assume anyone *viewing* your archives will be able to see any cookies, session tokens, or private URLs passed to ArchiveBox during archiving.*
-> *Make sure to secure your ArchiveBox data and don't share snapshots with others without stripping out sensitive headers and content first.*
+
+CAUTION: Assume anyone viewing your archives will be able to see any cookies, session tokens, or private URLs passed to ArchiveBox during archiving.
+Make sure to secure your ArchiveBox data and don't share snapshots with others without stripping out sensitive headers and content first.
+
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Publishing-Your-Archive
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install#setting-up-a-chromium-user-profile
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#chrome_user_data_dir
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#cookies_file
+Learn More
+
@@ -921,28 +950,27 @@ Be aware that malicious archived JS can access the contents of other pages in yo
Expand to see risks and mitigations...
-```bash
-# visiting an archived page with malicious JS:
+# visiting an archived page with malicious JS:
https://127.0.0.1:8000/archive/1602401954/example.com/index.html
# example.com/index.js can now make a request to read everything from:
https://127.0.0.1:8000/index.html
https://127.0.0.1:8000/archive/*
# then example.com/index.js can send it off to some evil server
-```
+
-The admin UI is also served from the same origin as replayed JS, so malicious pages could also potentially use your ArchiveBox login cookies to perform admin actions (e.g. adding/removing links, running extractors, etc.). We are planning to fix this security shortcoming in a future version by using separate ports/origins to serve the Admin UI and archived content (see [Issue #239](https://github.com/ArchiveBox/ArchiveBox/issues/239)).
-
-> *NOTE: Only the `wget` & `dom` extractor methods execute archived JS when viewing snapshots, all other archive methods produce static output that does not execute JS on viewing.*
-> *If you are worried about these issues ^ you should disable these extractors using `archivebox config --set SAVE_WGET=False SAVE_DOM=False`.*
-
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview
-- https://github.com/ArchiveBox/ArchiveBox/issues/239
-- https://github.com/ArchiveBox/ArchiveBox/security/advisories/GHSA-cr45-98w9-gwqx (`CVE-2023-45815`)
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#publishing
+
+NOTE: Only the wget & dom extractor methods execute archived JS when viewing snapshots, all other archive methods produce static output that does not execute JS on viewing.
+If you are worried about these issues ^ you should disable these extractors using:
archivebox config --set SAVE_WGET=False SAVE_DOM=False.
+
+Learn More
+
@@ -958,13 +986,14 @@ For various reasons, many large sites (Reddit, Twitter, Cloudflare, etc.) active
-- Set [`CHROME_USER_AGENT`, `WGET_USER_AGENT`, `CURL_USER_AGENT`](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#curl_user_agent) to impersonate a real browser (instead of an ArchiveBox bot)
-- Set up a logged-in browser session for archiving using [`CHROME_DATA_DIR` & `COOKIES_FILE`](https://github.com/ArchiveBox/ArchiveBox/wiki/Chromium-Install#setting-up-a-chromium-user-profile)
-- Rewrite your URLs before archiving to swap in an alternative frontend thats more bot-friendly e.g.
- `reddit.com/some/url` -> `teddit.net/some/url`: https://github.com/mendel5/alternative-front-ends
+
-
-In the future we plan on adding support for running JS scripts during archiving to block ads, cookie popups, modals, and fix other issues. Follow here for progress: [Issue #51](https://github.com/ArchiveBox/ArchiveBox/issues/51).
+In the future we plan on adding support for running JS scripts during archiving to block ads, cookie popups, modals, and fix other issues. Follow here for progress:
Issue #51.
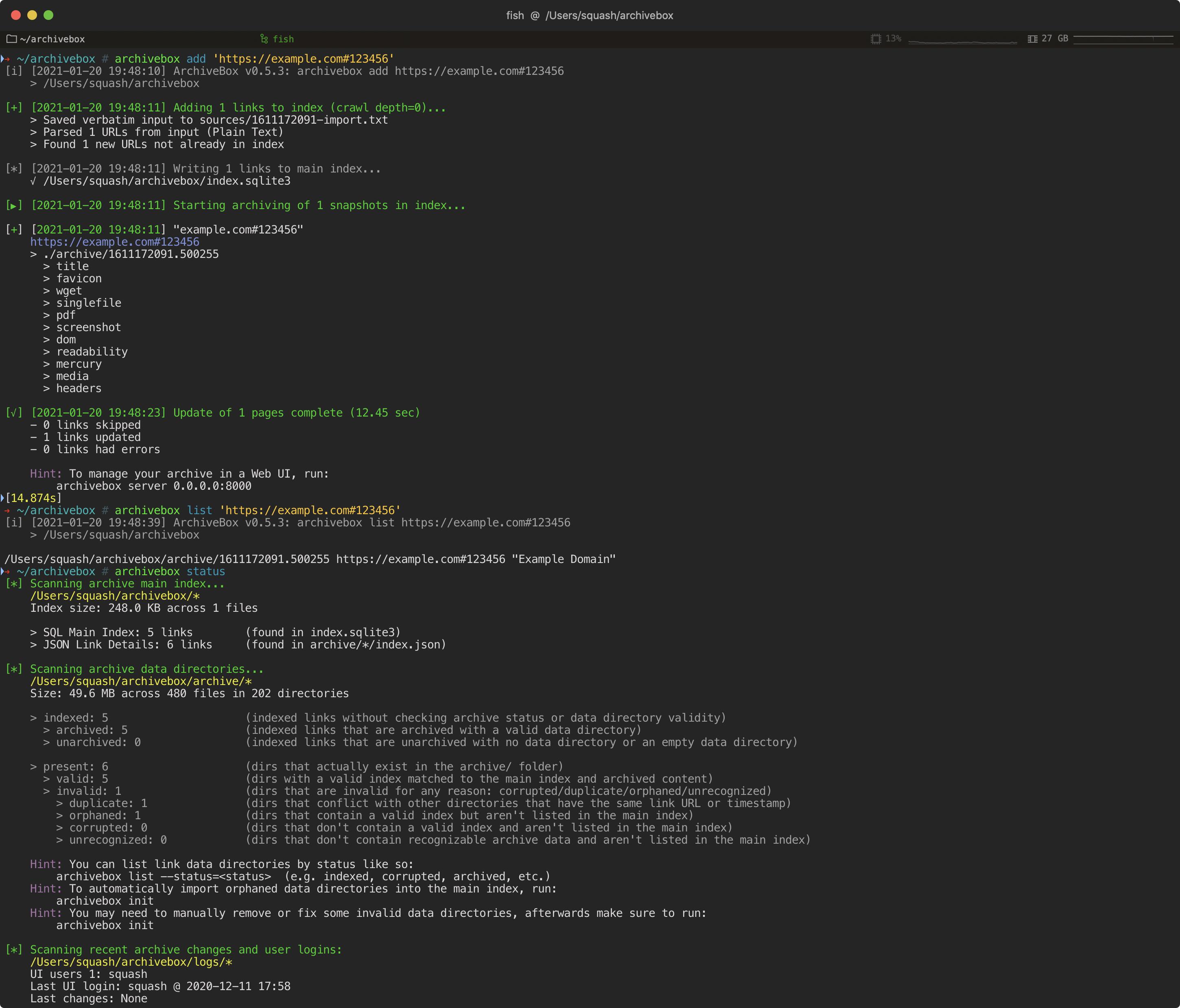
@@ -977,27 +1006,27 @@ ArchiveBox appends a hash with the current date `https://example.com#2020-10-24`
-Click to learn how the `Re-Snapshot` feature works...
+Click to learn how the Re-Snapshot feature works...
Because ArchiveBox uniquely identifies snapshots by URL, it must use a workaround to take multiple snapshots of the same URL (otherwise they would show up as a single Snapshot entry). It makes the URLs of repeated snapshots unique by adding a hash with the archive date at the end:
-```bash
-archivebox add 'https://example.com#2020-10-24'
+archivebox add 'https://example.com#2020-10-24'
...
archivebox add 'https://example.com#2020-10-25'
-```
+
The  button in the Admin UI is a shortcut for this hash-date multi-snapshotting workaround.
-Improved support for saving multiple snapshots of a single URL without this hash-date workaround will be [added eventually](https://github.com/ArchiveBox/ArchiveBox/issues/179) (along with the ability to view diffs of the changes between runs).
+Improved support for saving multiple snapshots of a single URL without this hash-date workaround will be added eventually (along with the ability to view diffs of the changes between runs).
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/issues/179
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#explanation-of-buttons-in-the-web-ui---admin-snapshots-list
+
button in the Admin UI is a shortcut for this hash-date multi-snapshotting workaround.
-Improved support for saving multiple snapshots of a single URL without this hash-date workaround will be [added eventually](https://github.com/ArchiveBox/ArchiveBox/issues/179) (along with the ability to view diffs of the changes between runs).
+Improved support for saving multiple snapshots of a single URL without this hash-date workaround will be added eventually (along with the ability to view diffs of the changes between runs).
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/issues/179
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#explanation-of-buttons-in-the-web-ui---admin-snapshots-list
+Learn More
+
@@ -1015,19 +1044,24 @@ Because ArchiveBox is designed to ingest a large volume of URLs with multiple co
**ArchiveBox can use anywhere from ~1gb per 1000 articles, to ~50gb per 1000 articles**, mostly dependent on whether you're saving audio & video using `SAVE_MEDIA=True` and whether you lower `MEDIA_MAX_SIZE=750mb`.
-Disk usage can be reduced by using a compressed/deduplicated filesystem like ZFS/BTRFS, or by turning off extractors methods you don't need. You can also deduplicate content with a tool like [fdupes](https://github.com/adrianlopezroche/fdupes) or [rdfind](https://github.com/pauldreik/rdfind). **Don't store large collections on older filesystems like EXT3/FAT** as they may not be able to handle more than 50k directory entries in the `archive/` folder. **Try to keep the `index.sqlite3` file on local drive (not a network mount)** or SSD for maximum performance, however the `archive/` folder can be on a network mount or slower HDD.
+Disk usage can be reduced by using a compressed/deduplicated filesystem like ZFS/BTRFS, or by turning off extractors methods you don't need. You can also deduplicate content with a tool like [fdupes](https://github.com/adrianlopezroche/fdupes) or [rdfind](https://github.com/pauldreik/rdfind).
+
+**Don't store large collections on older filesystems like EXT3/FAT** as they may not be able to handle more than 50k directory entries in the `archive/` folder.
+
+**Try to keep the `index.sqlite3` file on local drive (not a network mount)** or SSD for maximum performance, however the `archive/` folder can be on a network mount or slower HDD.
If using Docker or NFS/SMB/FUSE for the `data/archive/` folder, you may need to set [`PUID` & `PGID`](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#puid--pgid) and [disable `root_squash`](https://github.com/ArchiveBox/ArchiveBox/issues/1304) on your fileshare server.
-#### Learn More
-
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#Disk-Layout
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#output-folder
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Usage#large-archives
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#puid--pgid
-- https://github.com/ArchiveBox/ArchiveBox/wiki/Security-Overview#do-not-run-as-root
+
Learn More
+
@@ -1048,31 +1082,31 @@ If using Docker or NFS/SMB/FUSE for the `data/archive/` folder, you may need to
-
- +
+
+
|
-
+
|
- +
+
|
- +
+
|
|
-
+
|
-
+
|
-
+
|
-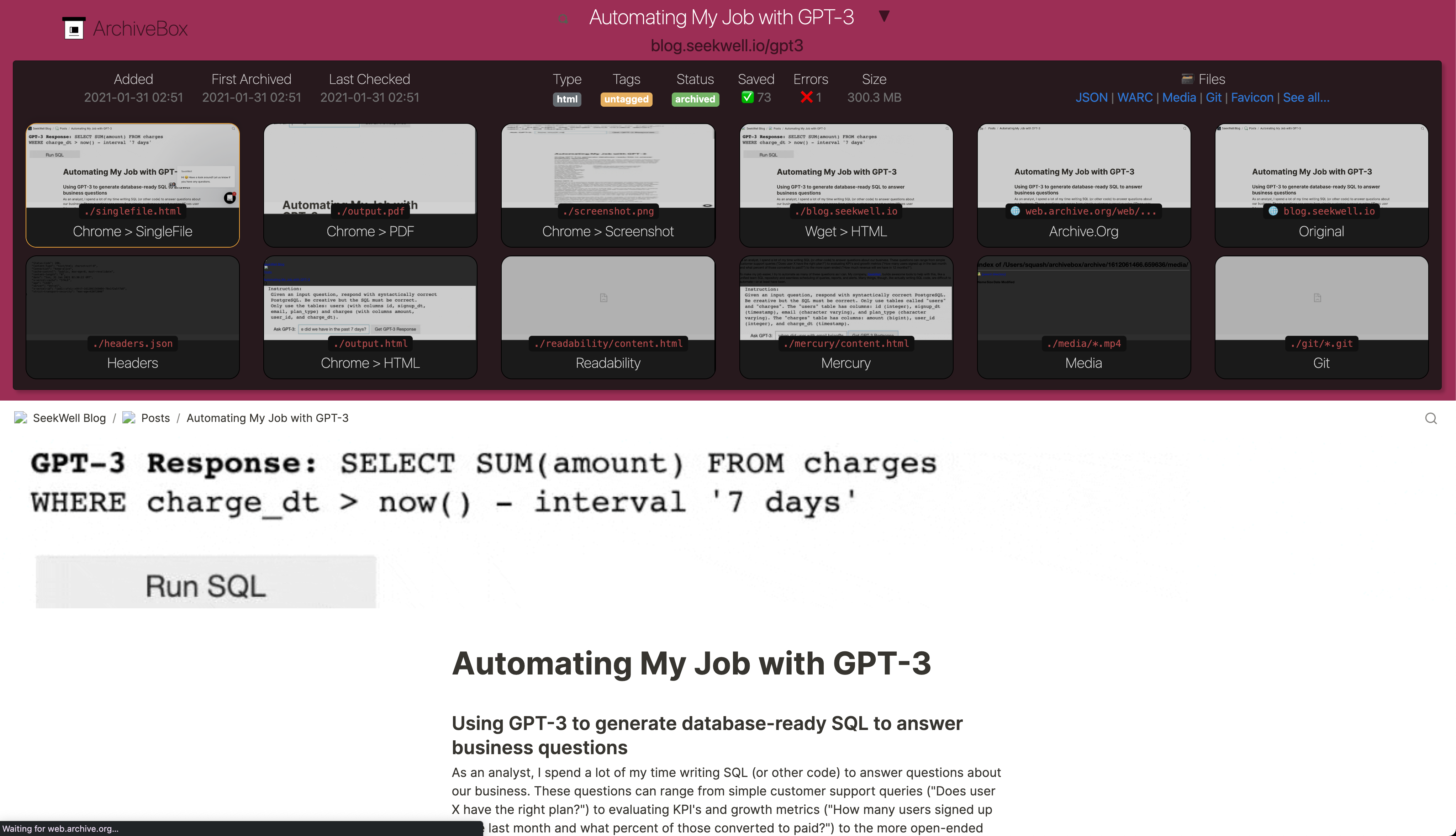 +
+
|
@@ -1103,7 +1137,7 @@ Whether it's to resist censorship by saving articles before they get taken down
@@ -1164,7 +1198,7 @@ ArchiveBox is neither the highest fidelity nor the simplest tool available for s

-Our Community Wiki strives to be a comprehensive index of the broader web archiving community...
+Our Community Wiki strives to be a comprehensive index of the web archiving industry...
- [Community Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki/Web-Archiving-Community)
@@ -1476,7 +1510,7 @@ Extractors take the URL of a page to archive, write their output to the filesyst
- [ArchiveBox.io Homepage](https://archivebox.io) / [Source Code (Github)](https://github.com/ArchiveBox/ArchiveBox) / [Demo Server](https://demo.archivebox.io)
- [Documentation Wiki](https://github.com/ArchiveBox/ArchiveBox/wiki) / [API Reference Docs](https://docs.archivebox.io) / [Changelog](https://github.com/ArchiveBox/ArchiveBox/releases)
- [Bug Tracker](https://github.com/ArchiveBox/ArchiveBox/issues) / [Discussions](https://github.com/ArchiveBox/ArchiveBox/discussions) / [Community Chat Forum (Zulip)](https://zulip.archivebox.io)
-- Social Media: [Twitter](https://twitter.com/ArchiveBoxApp), [LinkedIn](https://www.linkedin.com/company/archivebox/), [YouTube](https://www.youtube.com/@ArchiveBoxApp), [Alternative.to](https://alternativeto.net/software/archivebox/about/), [Reddit](https://www.reddit.com/r/ArchiveBox/)
+- Find us on social media: [Twitter](https://twitter.com/ArchiveBoxApp), [LinkedIn](https://www.linkedin.com/company/archivebox/), [YouTube](https://www.youtube.com/@ArchiveBoxApp), [SaaSHub](https://www.saashub.com/archivebox), [Alternative.to](https://alternativeto.net/software/archivebox/about/), [Reddit](https://www.reddit.com/r/ArchiveBox/)
---
@@ -1490,7 +1524,7 @@ Extractors take the URL of a page to archive, write their output to the filesyst


-ArchiveBox operates as a US 501(c)(3) nonprofit (sponsored by HCB), donations are tax-deductible.
+ArchiveBox operates as a US 501(c)(3) nonprofit (sponsored by HCB), direct donations are tax-deductible.

